Abstract
The goal of our final project was to add AR visuals to stadium performances and football games while learning about computer vision. We had a video of the field and a tabletop aerial view of the field to test with. We developed an iOS application essentially started from scratch since this is a very atypical use case for Apple’s ARKit.To accomplish real-time performance, we wrote all the heavy computation for the GPU and were forced to be clever with how we parallelized each of our image analysis steps. We developed a series of GPU kernel functions to pull lines out of each image. We then classified each pixel. Next, we identified relevant points on the field. Finally, we implemented visuals including a teapot in a stadium, teddy bear, and others.
Technical Approach
We began by trying to use Hough Line Transform to identify lines in our frames. This approach bins each detected edge pixel (from Sobel detection or otherwise) into each line it could be part of. Since we represent lines in Hesse normal form, this means each pixel could be part of 180 different lines. Incrementing 180 different values constitutes 360 memory accesses per pixel. This was too expensive and noisy when we went from tabletop demos to the field demo. Furthermore, we had to run it on the CPU since the algorithm would lead to lots of memory access races when run in parallel.
 Hough transform on tabletop example.
Hough transform on tabletop example.
 Hough transform on stadium frame capture (lines all over the place).
Hough transform on stadium frame capture (lines all over the place).
We noticed that the field had lots of rich segmentation information, so we developed a series of GPU kernel functions to pull this out of each image. These were either kernel functions applied to each pixel or each vertical stripe of pixels. The massive parallelization of the GPU allowed us to run multiple of these functions over each pixel for every single frame while preserving 60 FPS real time performance.
 Screenshot of green-detection kernel function.
Screenshot of green-detection kernel function.
 Screenshot of custom edge function to identify green-white gradients.
Screenshot of custom edge function to identify green-white gradients.
In one such kernel function, we used logistic regression to classify each pixel as green, white, or gold according to its RGB values. Then, we analyzed these filtered pixels’ proximity to each other to identify field lines and make guesses about their locations on the field.
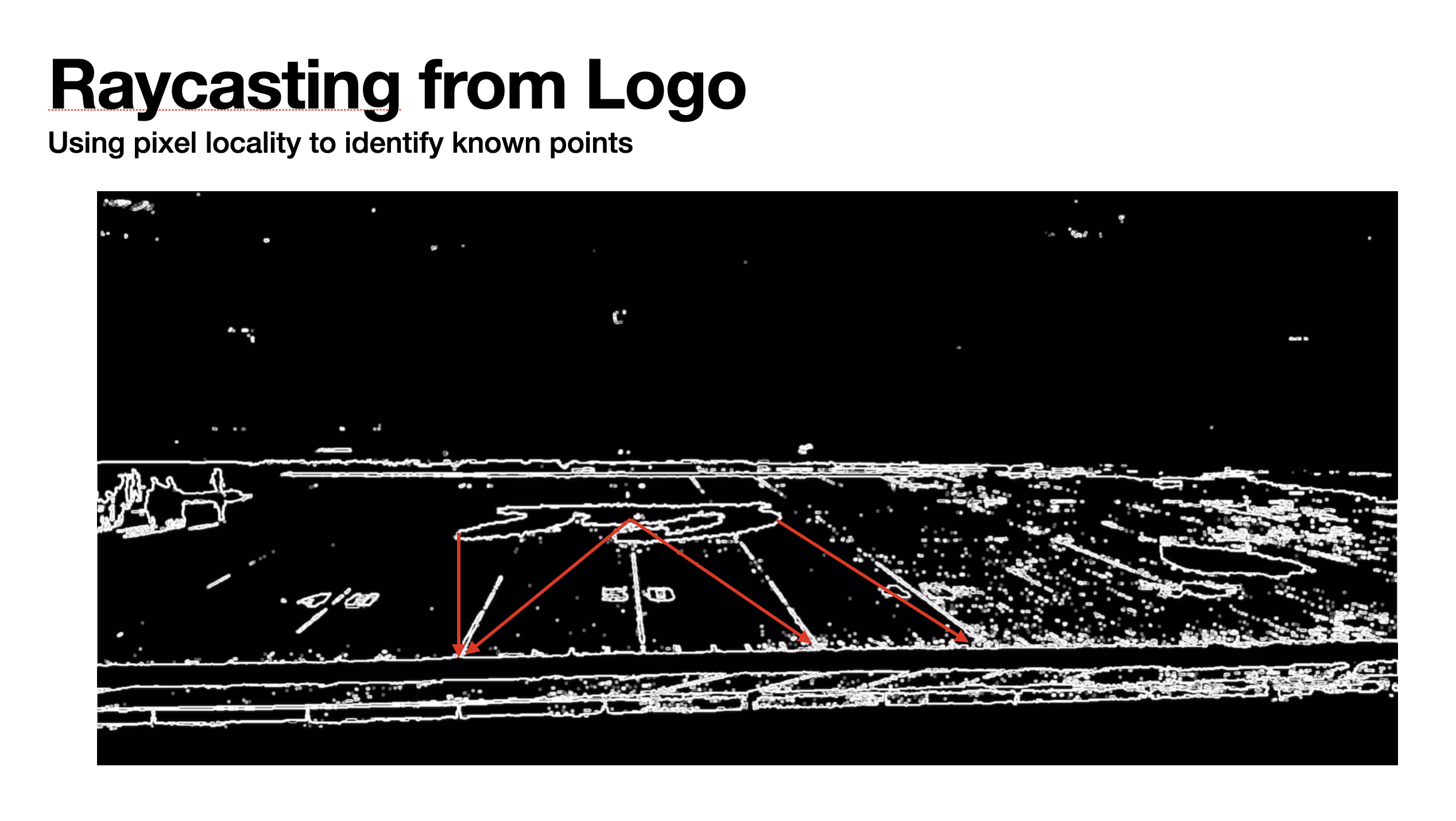 Raycasting overview.
Raycasting overview.
After some denoising, we got some reasonable outputs. We raycasted from the Cal Logo in different directions to intersect points on the field. This mapped a set of 2D pixel coordinates to their 3D world coordinates. Going from three of these mappings to a transformation matrix is called the perspective-three-point problem, which we solved using a public algorithm.
The goal of such an algorithm is to calculate the extrinsic matrix, establishing the relationship between the camera and the target object in 3D space. This encodes rotation and translation of the camera from a defined origin point. Then, we can multiply this matrix with an intrinsic matrix, representing the internal parameters of the camera to get the projection matrix. These internal features include known parameters like focal length and can encode simple distortions, though we plan to ignore those and assume a pinhole camera model.
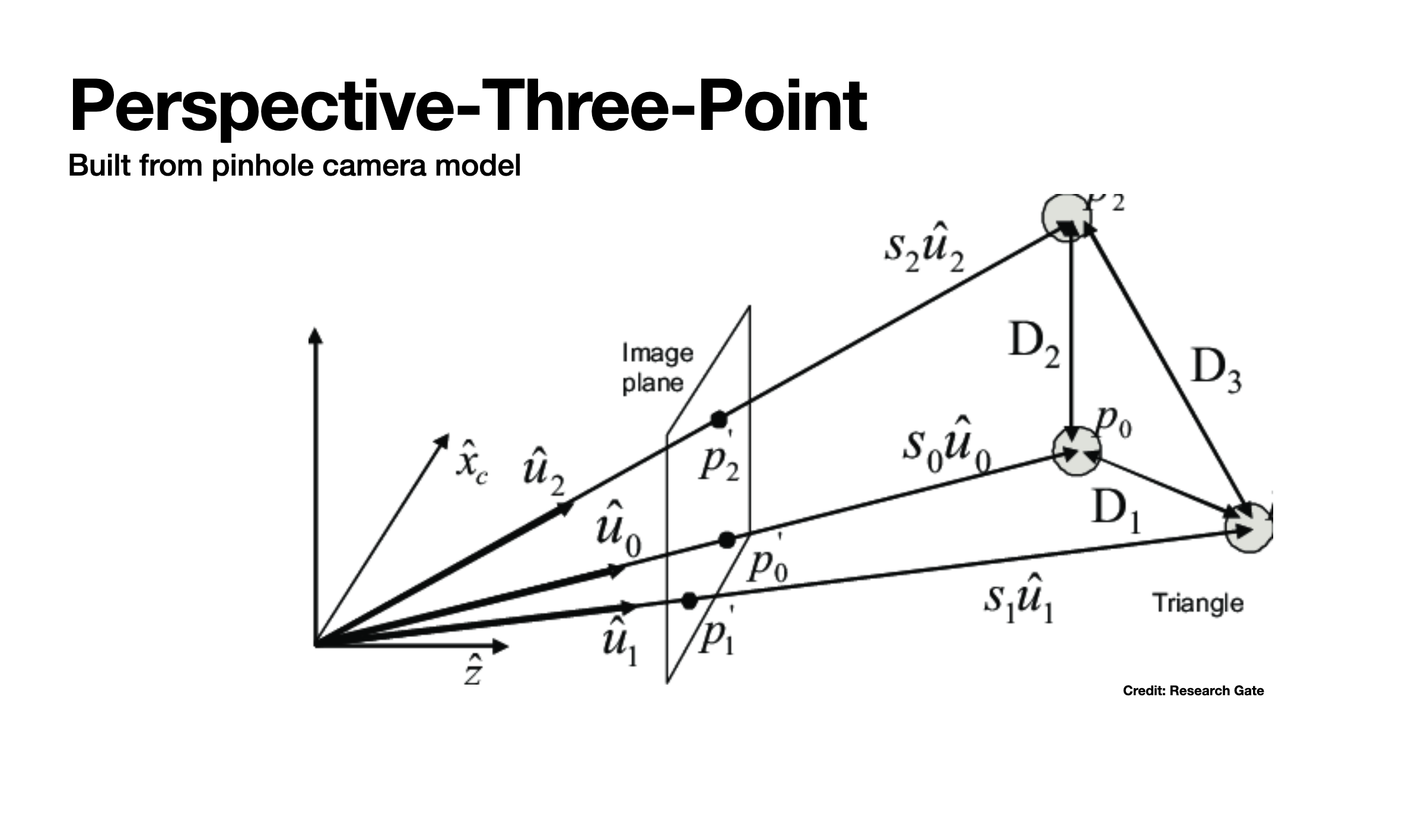 Perspective-three-point problem.
Perspective-three-point problem.
The perspective-three-point algorithm we chose involves building a quartic polynomial from those mappings and finding its roots. Then, it confirms which root is the correct solution by verifying it with a fourth point. We’ve debugged the process up to the quartic equation solver, so full position-invariant tracking does not work yet. We approximated it by fixing the phone’s starting location and carrying out some more basic trigonometry calculations using our identified points. This solution updates the tracking based on the points each frame, so it’s very subject to noise between captured frames.
We think we’re very close to a solution that will work from any location in the student section. Our final solution will be much less jittery as well, since we can derive a camera localization from a subset of high quality frame analyses then update the tracking using the gyroscope and accelerometer data. We can further improve this solution by using maximum likelihood estimation to compute the extrinsic parameters that most likely explain data recorded over many frames.
Finally, we plan to use Apple’s SceneKit to produce more convincing 3D visuals. Currently, they’re simple un-textured meshes with single point light sources. We might be able to estimate the location of the Sun using time of day and compass data then shade to match the scene’s real world light.
Results
Final Project Video Link: https://youtu.be/xeA3LtNYQFo
 Cal Logo feature points superimposed (red triangles)
Cal Logo feature points superimposed (red triangles)
|
 Other field feature points superimposed
Other field feature points superimposed
|
 Teddy bear model tracked onto football field
Teddy bear model tracked onto football field
|
 Utah teapot tracked onto football field
Utah teapot tracked onto football field
|
Watch the video for more visuals!
References
Project 3-Point Algorithm: https://www.youtube.com/watch?v=N1aCvzFll6Q
Project 3-Point Algorithm Paper: http://www.ipb.uni-bonn.de/html/teaching/photo12-2021/2021-pho1-23-p3p.pptx.pdf
Direct Linear Transform: https://www.cs.toronto.edu/~urtasun/courses/CV/lecture09.pdf
Camera Calibration: https://cvgl.stanford.edu/teaching/cs231a_winter1415/prev/projects/LeviFranklinCS231AProjectReport.pdf
Swift Linear Regression Solution: https://aquarchitect.github.io/swift-algorithm-club/Linear%20Regression/
Contributions
- David: Set up project, developed GPU kernel functions. Worked on perspective-three-point algorithm.
- Ethan: Developed green, white, gold classifier. Developed idea for identifying relevant field points.
- James: Developed raycasting of Cal Logo, worked on mapping of 2D pixel coordinates to 3D world coordinates. Worked on perspective-three-point algorithm.
- Shilpa: Made and developed all webpages and submissions. Helped develop raycasting for Cal Logo.
